
Hello! Today we leave PowerApps aside, but we head into yet another area way out of my confort zone: Programmatic creation and refresh of custom M Partitions! this is not something I really wanted to do, but I found myself with no other option available. Are you ready? Let’s do it.
As the title says, I had never done anything like it and I tried to solve the problem with all the ways I could imagine before jumping into this. So what was the situation? Well, this are like this:
- Customer has almost all their cloud infrastructure in AWS
- Customer has A LOT of data
- Customer uses Qlik Sense but for this particular project decided to try Power BI as there are already some substantial shortcomings with Qlik Sense.
- End-Users need an analytical tool but for operational purposes. They operate in a low latency industry and deal with many providers. They want to monitor that everything is fine, and if it’s not be able to call the supplier to get it fixed. They need fresh data every 15 min.
- Our chosen architecture is a AWS Glue ETL executing python and generating parquet files. These files with along with some dimension tables are stored in S3 and exposed through AWS Athena SQL Endpoint.
So far so good. We knew that the connector with AWS Athena was not great, but hey, its a SQL datasource so if it takes too long to load we can always use hybrid tables right?
Looking for the right architecture
Well, this is one of the most challenging projects I’ve faced. Our first attempt to load the data was terrible. They had placed the gateway on-premise, and to load the data fro 1 day, it took 5h and failed
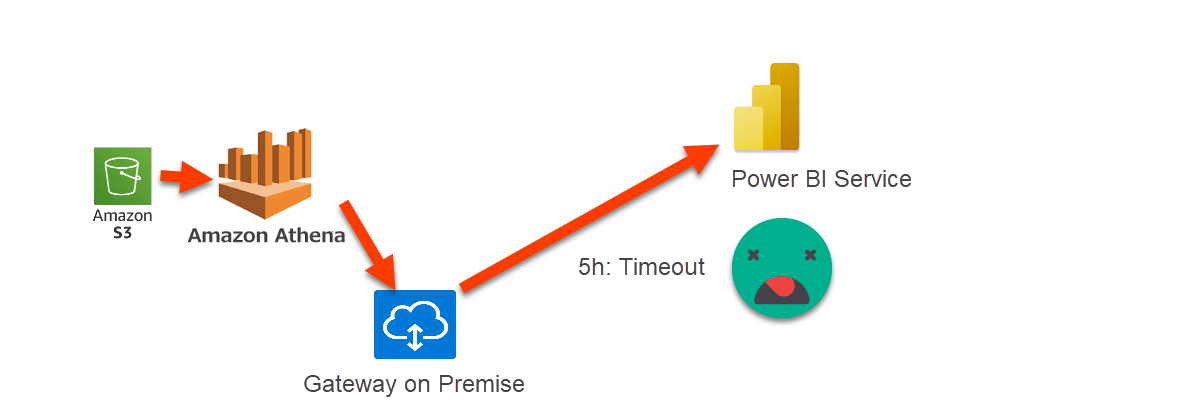
What I did next was to set up a gateway on a Virtual Machine in Azure and try again. This time it completed, but took 3h. This was orders of magnitude slower than required.
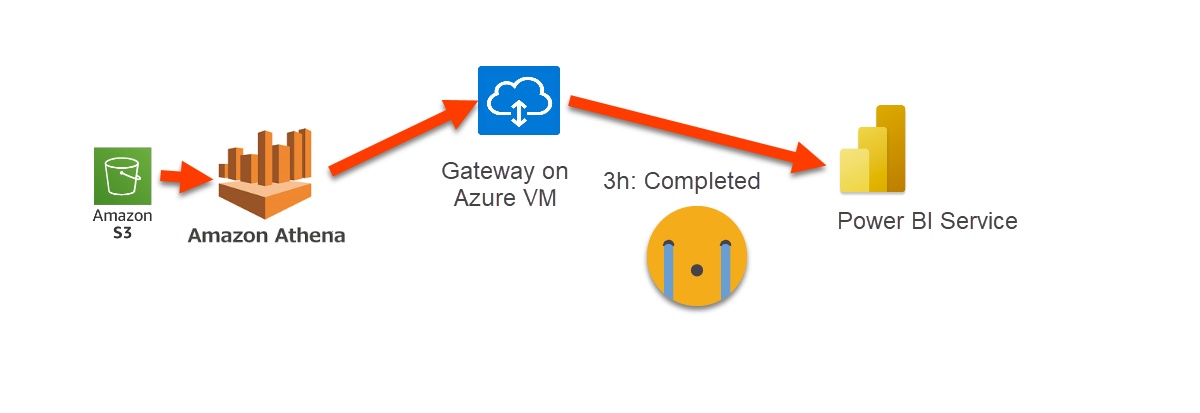
Then we tried to see if hybrid tables or even basic direct query could save the day. Even without considering the potential cost that it could have running a direct query against Athena, we had to discard the option. Whenever I set up a filter on a dimension I would get an error saying that «the query is too complex». What?? just one filter, I promise. I realized that the AWS Athena connector does not receive much love from either Microsoft or AWS.
Next we tried to see if it would make sense to write the parquet files in Azure and read directly the parquet files from there. Of course all of these was still planning to use the native incremental refresh functionality, so the decision point was how long does it take to load a whole day of data. Even with that, it would take an 1h and 15 min or so to load a full day of data (and it was not really a full day so in production it could be even worse).
I kept thinking and even though the idea was to develop the project using PPU licenses, I tried to see if Fabric could be the answer. I tried creating shortcuts to S3 and even to the parquet files me manually moved to Azure. It did not seem to work easily since the parquet files where not in the delta format…
At this point we decided to bit the red pill and enter the world of near real time tabular models.

I revisited the «Mastering Tabular» video course I completed a few months ago to see what I could get out of it. Indeed they explain such scenario is possible and show a few TMSL scripts, but in order to build a near real time solution they point to a Project in Microsoft’s Analysis Services repository that apparently served as the basis to build the incremental refresh policy. I did try to open the project and make sense of it, but there were some references failing I could not get rid of, and overall seemed way too complex.
After all, all I wanted is to create 15 min partitions on my fact tables and refresh the correct partition every 15 min.
So I stared bugging my network for advice (shout out to Gerhard Brueckl, Greg Baldini and others who helped me out). At first I tried looking at Azure Devops pipelines, and YAML and so on and got completely numb. I had to learn like 2 new languages (PowerShell and YAML) to do that?? really?

After some more googling and more bugging of my colleagues I saw that I could use Powershell to execute a tabular editor c# script against a model, and that felt good as I can write some c# scripts and I have my setup where intellisense plays on my side! Still I was stuck with the YAML thing and PowerShell also felt like black magic to me.
Then it struck me. Having to download tabular editor every 15 min does not feel as a very wise thing to do, right? why not just execute the PowerShell scripts in a virtual machine? Even better, why not execute the scripts from the gateway machine itself? Might not be the best choice, but for now this is the only model they have, so why not. I had already my test gateway machine so I could access it and try stuff.
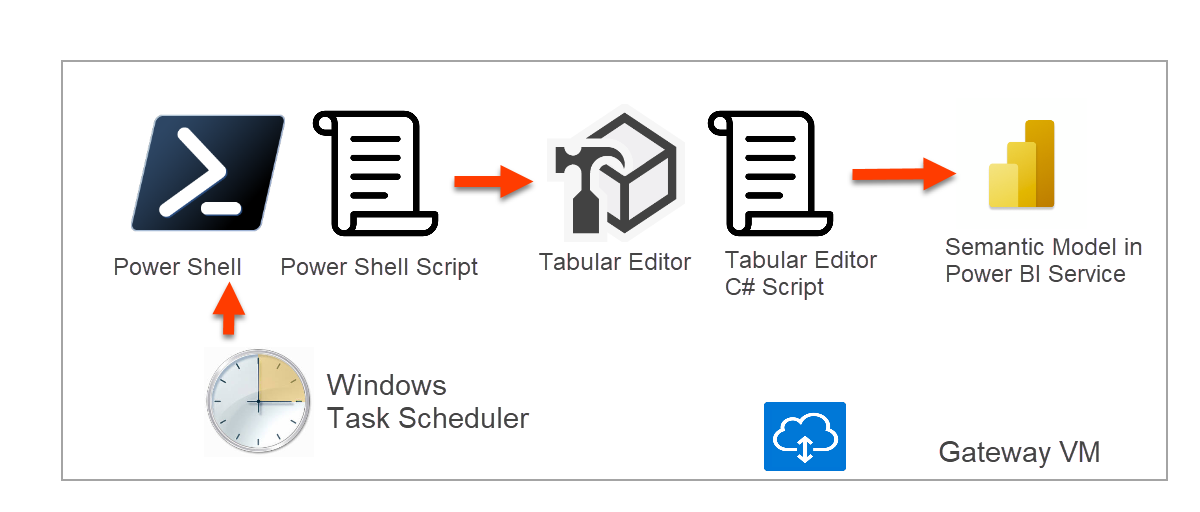
But hey, let’s step back and go step by step:
Setting up your model for near real time
When you create a custom M partition, you need to provide the M-code for it. so you might want it to be as easy as possible. Since I had previously tried to use the native incremental refresh, I already had the two parameters (RangeStart, RangeEnd) filtering my source data. This time of course I had to make sure that these where filtering the datetime column of the source that would determine the data that had to go in each 15-min partition.
![]()
Once I had this I duplicated the query, I disabled the load, and I clicked on the «Create Function» option of the right click menu. This created a function with two date-time parameters that would return the data for of that fact table between those two timestamps.
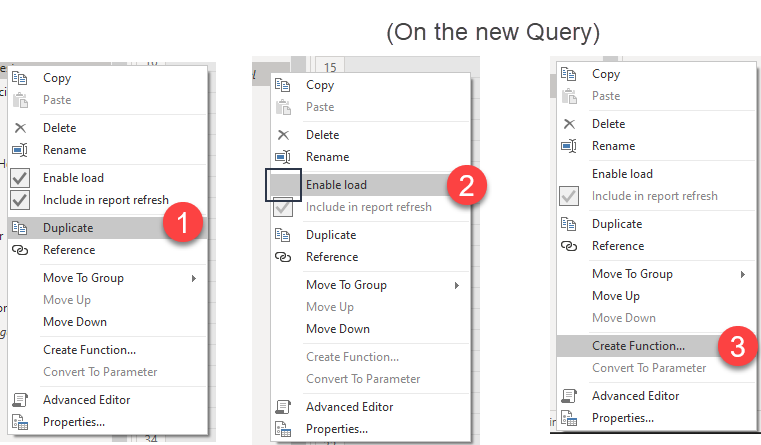
The reason why I duplicated first que query is because once you create the function, it is connected to the query and I didn’t want that sort of connection with the real fact table, because in a minute we’ll need to add a one more step that we don’t want on the function.
To make things even easier, you can provide two timestamps and click on Invoke Function. This will provide a new query using the function. This is basically the code that we will need for our Custom M-Partitions.
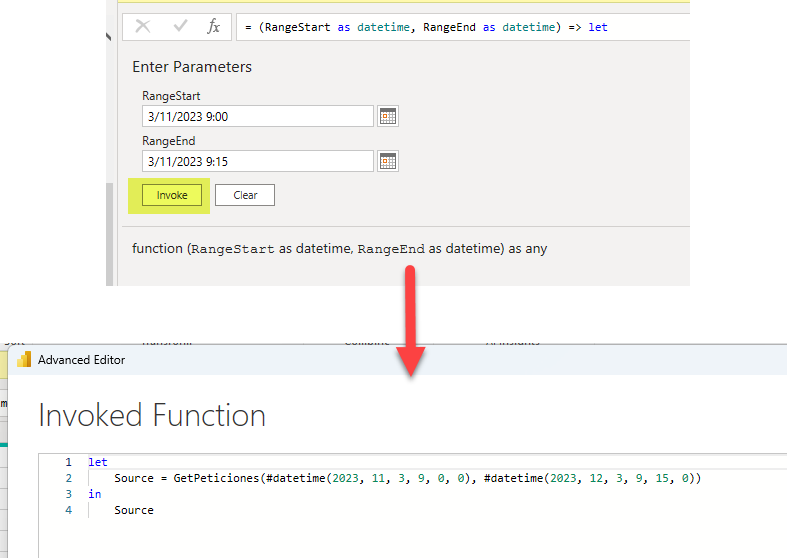
Of course we don’t want all the partitions to be exactly like this. Each partition will need the correct values for the two arguments of the function. So in a notepad or something we will copy the code and edit it to something like
let
Source = GetPeticiones({0}, {1})
in
Source
If you have read my article on Industrializing Calculation Groups, you will know where this is going. In C# scripts we can use String.Format() function, where we first provide the string with the placeholders {0},{1},etc and then we provide the actual values for those placeholders. So this is our partition template! Where can we store it? In annotations of course! That’s where we store all the extra metadata we need to store somewhere. Annotations can be created programmatically as I have shown in other articles, but in this case we will generate it manually as this is a one-time thing. Each table needs an annotation with it’s own partition template.
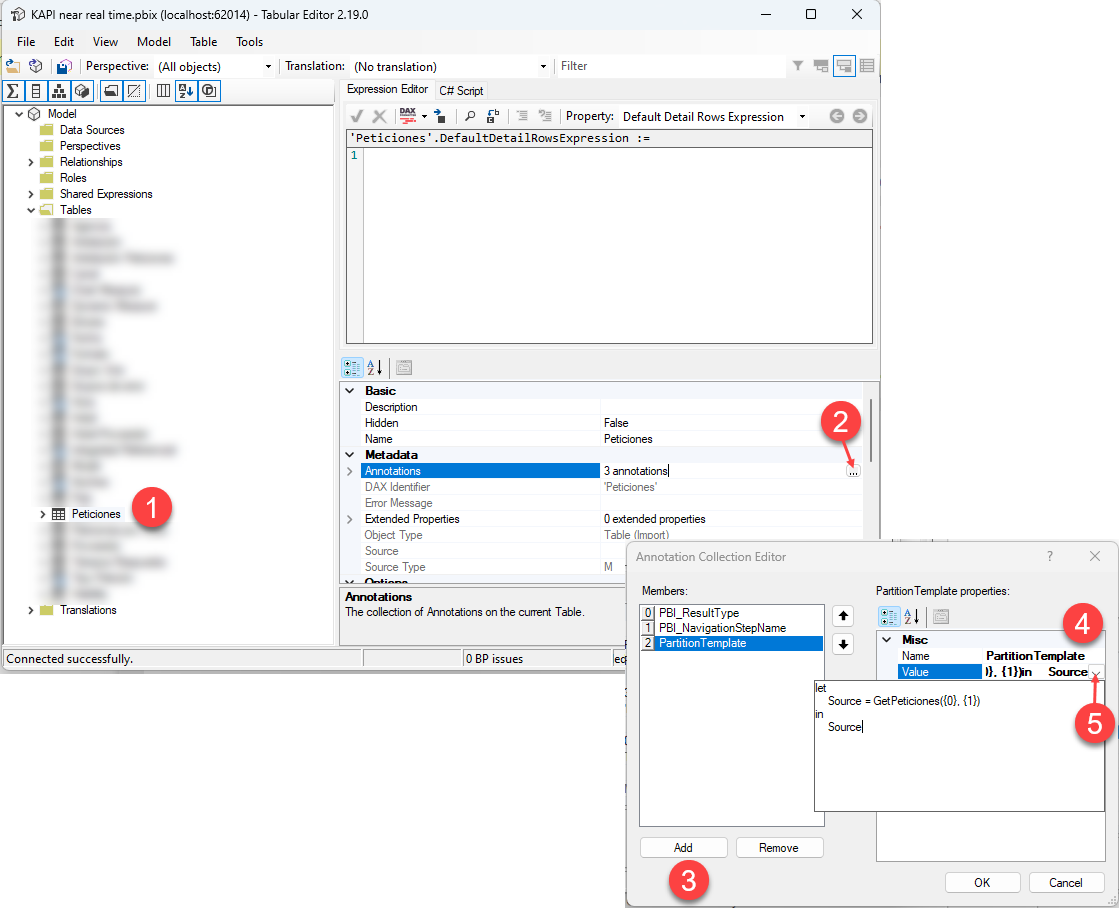
The process is quite straightforward if you know what to look for. There’s a couple gotcha’s though. You need to expand the value box to be able to paste a multiline text, otherwise only the first line (a lonely «let») gets copied. Also, even though the code looks great in the annotation, I’ve found that when you read it later, the line breaks are gone and then the «in» keyword appears together with the previous parenthesis and the whole thing causes an error. You may use this opportunity to «flatten» your code and make sure there’s an space before the «in» keyword. You need to repeat the process for all the tables that require 15 min partitions, probably all the fact tables. Make sure that all the annotations have the same name, that will make your life much easier later when we write the scripts. I used the name «PartitionTemplate» but feel free to use any other name you like.
Oh, and before I forget, since we will be loading all the data through this custom M partitions, what should I do with the current partition?? I’m not sure whats the best practice there, but I wanted to keep the columns and none of the rows, so I went to «Keep top rows» and set it up to 0 rows. This added added the following step leaving my table empty.

Authoring a Tabular Editor C# Script to create partitions
After looking at several examples it looks like you can launch Tabular Editor 2 from the command line against certain model (local or published) and execute a script. Thus, I needed first a script that created such partitions and later we’ll see how to specify the model and so on. Writing the script itself was quite straightforward.
//DateTime currentTimeStamp = DateTime.Now;
DateTime currentTimeStamp = new DateTime(2023, 11, 3, 0, 0, 0);
foreach (Table t in Model.Tables.Where(tb => tb.GetAnnotation("PartitionTemplate") != null))
{
string partitionTemplate = t.GetAnnotation("PartitionTemplate");
DateTime firstPartition = new DateTime(currentTimeStamp.Year, currentTimeStamp.Month, currentTimeStamp.Day, 0, 0, 0);
DateTime LastPartition = new DateTime(currentTimeStamp.Year, currentTimeStamp.Month, currentTimeStamp.Day + 1, 0, 0, 0);
DateTime cp = firstPartition;
while (cp < LastPartition)
{
DateTime np = cp.AddMinutes(15);
string startDateTimeM = string.Format(@"#datetime({0},{1},{2},{3},{4},0)", cp.Year, cp.Month, cp.Day, cp.Hour, cp.Minute);
string endDateTimeM = string.Format(@"#datetime({0},{1},{2},{3},{4},0)", np.Year, np.Month, np.Day, np.Hour, np.Minute);
string partitionName = cp.ToString("yyyyMMdd_HHmm");
string partitionExpression = string.Format(partitionTemplate, startDateTimeM, endDateTimeM);
if(!t.Partitions.Any(pt => pt.Name == partitionName)) {
t.AddMPartition(partitionName, partitionExpression);
}
cp = np;
}
}
The expression Model.Tables.Where(tb => tb.GetAnnotation(«PartitionTemplate») != null) will return the tables with the annotation, so our fact tables.
As you can see we pick the current timestamp and from here we define that the first partition will start at 0:00 (that makes more sense to me than 12 AM, sorry) and we will create partitions until reaching the same time but from one day later. This might need some tuning when going to production, but in theory it could be enough. «cp» is «currentPartition» and «np» is NextPartition. Next PArtition starts 15 min later than the current one, and is used to define the end of the current partition.
string startDateTimeM = string.Format(@"#datetime({0},{1},{2},{3},{4},0)", cp.Year, cp.Month, cp.Day, cp.Hour, cp.Minute);
string endDateTimeM = string.Format(@"#datetime({0},{1},{2},{3},{4},0)", np.Year, np.Month, np.Day, np.Hour, np.Minute);
Here is where we build the small bits that need to go in the PartitionTemplate code on the next line.
We also put some protection to prevent executing code that would create a partition that already exists. This happened during my testing and it kind of froze everything for a while. Indeed LINQ expreessions are quite convenient.
Authoring a PowerShell script to execute a Tabular Editor C# script
Here I didn’t really author much. I just got some code from Gerhard and made it work for me.
# $env:TabularEditorRootPath is set in Donwload-TabularEditor !
$env:TabularEditorRootPath = "C:\Program Files (x86)\Tabular Editor"
$executable = Join-Path $env:TabularEditorRootPath "TabularEditor.exe"
$params = @(
"""G:\[...]\Model.bim"""
"-SCRIPT ""G:\[...]\createDailyPartitions.csx"""
"-B ""G:\[...]\model.bim"""
)
Write-Host "Executing: $executable $($params -join " ")"
$p = Start-Process -FilePath $executable -Wait -NoNewWindow -PassThru -ArgumentList $params
$p.Close()
As you can see Powershell uses lot’s of $ and » and –
I also have little idea on really how to use the parameters such as the -B thing. But this worked against a model.bim file that I had stored in my machine.
Next step was to execute something similar against the deployed model in Power BI Service. This took some effort, as you need to authenticate against the service, and I did have some typos on my code, so things where not working and well, you never really know where the problem is. In theory you can use an App Registration (aka Service Principal) but I did not succeed. At last, I was lucky enough that for this project I was using an MFA-disabled account and I could manage to make it work with a code like this:
# $env:TabularEditorRootPath is set in Donwload-TabularEditor ! $env:TabularEditorRootPath = "C:\Program Files (x86)\Tabular Editor" $executable = Join-Path $env:TabularEditorRootPath "TabularEditor.exe" $params = @( """Provider=MSOLAP;Data Source=<XMLA Endpoint>;User ID=<Email>;Password=<Password>;Persist Security Info=True;Impersonation Level=Impersonate""" """<Dataset Name>""" "-SCRIPT ""<absolute path to C# Scrpt>""" "-D" ) Write-Host "Executing: $executable $($params -join " ")" $p = Start-Process -FilePath $executable -Wait -NoNewWindow -PassThru -ArgumentList $params
The XMLA endpoint can be copied from the Workspace Settings at the very end of the «Premium» tab
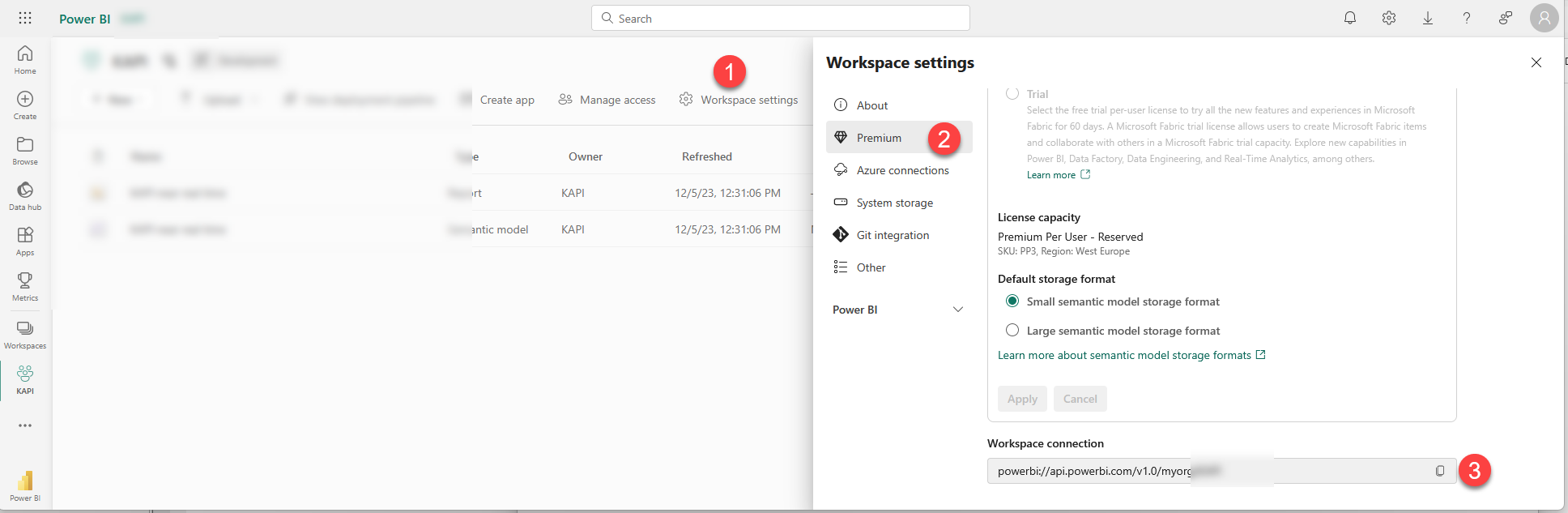
Just to be clear the <> need to be replaced as well, so that <XMLA Endpoint> becomes just powerbi://api.powerbi.com/v1.0/myorg/*** . Also the path has already all the double quotes it needs, just replace <absolute path to C# Scrpt> by the path itself. The dataset name also already has the double quotes it needs and it may have spaces and so on.
I know that having the password visible is terrible, but this is as far as my knowledge goes at this point, and in any case you still have the security to enter the machine, so it’s not like everyone can see it.
Automating the execution of a PowerShell Script
As you may recall from earlier in this same article we mentioned that we can automate the execution of the powershell script with Windows Task Scheduler. It does not sound like the most hype’d tool to automate stuff, but at this point I’m happy with anything that works. (Remember that we need to set this up on a Virtual Machine that is always on! In this case we are using the Virtual Machine where the gateway runs. )
Windows task scheduler comes together with windows, but getting to it is a bit tricky. If you search for it you will not find it, but you’ll see how to do it!
so the first method did not work for me, but it was telling me about another method… (maybe the privileges thing is what makes it not show up at first)
aaaand…
Bingo!
Just be aware that you cannot execute a Powershell script directly! I created a task and when it asks you what you want it to do it suggests you can specify a program or script…
After some failed attempts at running the scripts automatically, I decided to google «how to automate a powershell script with Windows Task Manager». This page provided some good guidance
In case the page goes bust, this is how it looked for me:
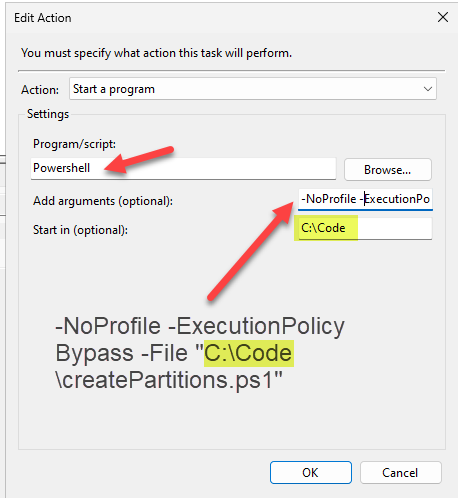
And you know what? IT WORKED!!
What about refreshing partitions?
Indeed! Creating the partitions is only part of the job, then you need to go and every 15 min execute the right partition. This part might need some fine tuning, but basically is another C# script that we can automte in the same way. The one creating partitions needs to be run once a day (right after midnight) and the other one every 15 min (probably starting at 0:15 refreshing the first partition? well it depends on when data becomes available. Once you see the code you can figure out how to fine tune it).
To refresh a partition I knew from the Mastering Tabular course that it can be done with a TMSL script which is basically a JSON file. But how can I execute it? hmmm. Then I remembered that Michael Kovalski had some C# script to refresh tables of a model or something in that direction so I checked his code to copy it in search of inspiration. And ineed I found it!
The code I found here was pretty much what I wanted. Based on a list of tables it creates the TMSL script to refresh them. Of course I wanted only to refresh certain partitions, but this time I was able to pick up something from the Mastering Tabular course, and see that I just needed one more line in the code.
Also I needed to build the name of the partition that needed refresh on the current time.
The code I have right now looks like this:
DateTime currentTimeStamp = DateTime.Now;
string currentMinutes = "";
if (currentTimeStamp.Minute < 15)
{
currentMinutes = "00";
} else if (currentTimeStamp.Minute < 30)
{
currentMinutes = "15";
}
else if (currentTimeStamp.Minute < 45)
{
currentMinutes = "30";
} else
{
currentMinutes = "45";
}
string currentPartition = currentTimeStamp.ToString("yyyyMMdd_HH") + currentMinutes;
// Initial parameters
string[] tableList = Model.Tables.Where(tb => tb.GetAnnotation("PartitionTemplate") != null).Select(t => t.Name).ToArray();
string type = "full"; // Options: 'full','automatic','calculate','clearValues'
// Additional parameters
string databaseName = Model.Database.Name;
string tmslStart = "{ \"refresh\": { \"type\": \"" + type + "\",\"objects\": [ ";
string tmslMid = "{\"database\": \"" + databaseName + "\",\"table\": \"%table%\",\"partition\": \"" + currentPartition + "\"} ";
string tmslMidDB = "{\"database\": \"" + databaseName + "\"}";
string tmslEnd = "] } }";
string tmsl = tmslStart;
string tablePrint = string.Empty;
string[] typeList = { "dataOnly","full", "automatic", "calculate", "clearValues" };
var sw = new System.Diagnostics.Stopwatch();
// Error check: processing type
if (!typeList.Contains(type))
{
Error("Invalid processing 'type'. Please enter a valid processing type within the 'type' parameter.");
return;
}
// Error check: validate tables
for (int i = 0; i < tableList.Length; i++)
{
if (!Model.Tables.Any(a => a.Name == tableList[i]))
{
Error("'" + tableList[i] + "' is not a valid table in the model.");
return;
}
}
// Generate TMSL
if (tableList.Length == 0)
{
tmsl = tmsl + tmslMidDB + tmslEnd;
}
else
{
for (int i = 0; i < tableList.Length; i++)
{
if (i == 0)
{
tmsl = tmsl + tmslMid.Replace("%table%", tableList[i]);
}
else
{
tmsl = tmsl + "," + tmslMid.Replace("%table%", tableList[i]);
}
tablePrint = tablePrint + "'" + tableList[i] + "',";
}
tmsl = tmsl + tmslEnd;
}
// Run TMSL and output info text
tablePrint = tablePrint.Substring(0, tablePrint.Length - 1);
sw.Start();
ExecuteCommand(tmsl);
sw.Stop();
Info("Processing '" + type + "' of tables: [" + tablePrint + "] partition " + currentPartition + " finished in: " + sw.ElapsedMilliseconds + " ms");
Since the name of the partition to refresh is the same for all the fact tables, I added the partition name on the «template» it builds when it declares the variable tmslMid. Since the TMSL will be a single command including all the partitions to be refreshed, is OK to do a full refresh, because it will load the data for each of them, but just to a single model recalc afterwards. Isn’t it nice? the ExecuteCommand can execute the TMSL script too. I saw somewhere that you can run them directly from PowerShell, but you see, I’m much more confortable with C# so this looks to me just perfect.
And that’s pretty much it!
With this approach we managed to load each 15 min partition in 5-10 min so we’re good! Also since it’s pure import, no huge bills from amazon should come.
What about deleting partitions you say?
Well, to be honest I have not yet got to that point, but all these can be done with TMSL scripts, so something very close to the second script should do it.
And merging partitions?
I know, probably I should be merging the partitions from yesterday and so on, but to be honest, unless performance is terrible I don’t think I’ll get into that…
Well, I hope you enjoyed the ride!
If you have some extra tips for me, please go ahead — very new to this kind of things.
Regards!!
Follow the conversation on Twitter and LinkedIn